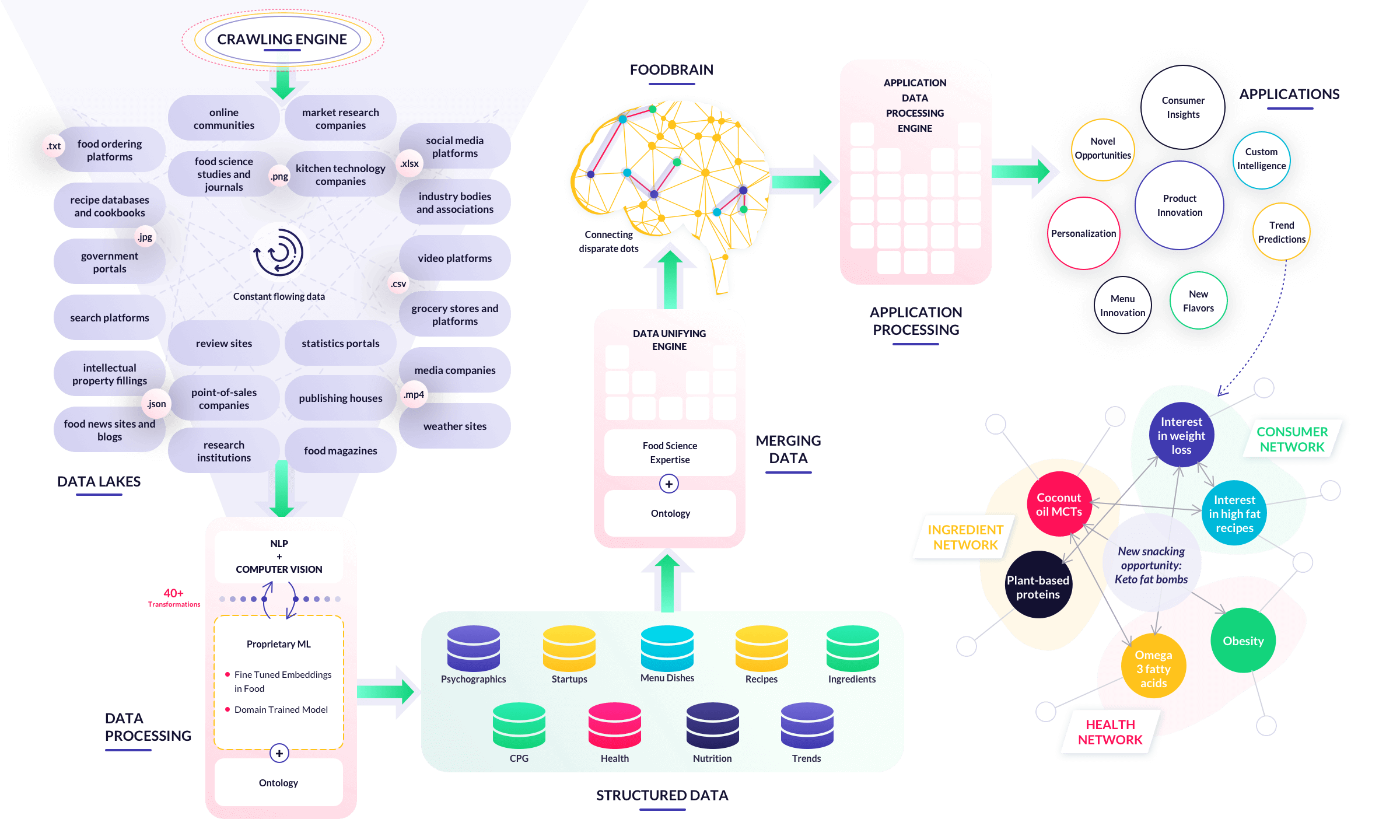
Our technology vision is to build an explainable machine intelligence that can replicate human
cognition in food.
The key highlights of this approach include:

Connecting disparate dots: We keenly observe the current world of food and beverage and then
analyze co-relations to it - such as consumer food interests, the impact of weather or the
regionality of a particular cuisine, creating a pattern that provides more actionable insights.
Powerful combination of domain expertise and tech: Having domain knowledge is not
just enough. Our technology combines both domain knowledge with structured data in such a way
that we are able to derive sense out of it.
Confluence of Food Science & AI: We use AI techniques, like Natural Language Processing
and Computer Vision technologies, to build structured information from unstructured data.
We do this by leveraging food science principles to establish relationships between these information
dots. Depending on the application or insight being delivered, the appropriate datasets and connection
types are used.
We collect information relating to the physical and chemical properties of ingredients and understand
how ingredient interactions impact a final recipe, to build insights that are valid and relevant to you.
Currently, our database contains volatile compounds for each ingredient, their sensory flavor profile,
and the nutritional breakdown of ingredients. We use publicly available data e.g. web, academic articles,
and patents, to get this information.